When we started building LLM features at Infonex, we did what everyone does: we wrote a prompt, eyeballed a few outputs, decided it "felt right," and shipped. Then a client would forward us a screenshot of the model confidently inventing a policy that didn't exist, and we'd go back, tweak the wording, eyeball it again, and ship again. We were optimizing for the demo, not the system.
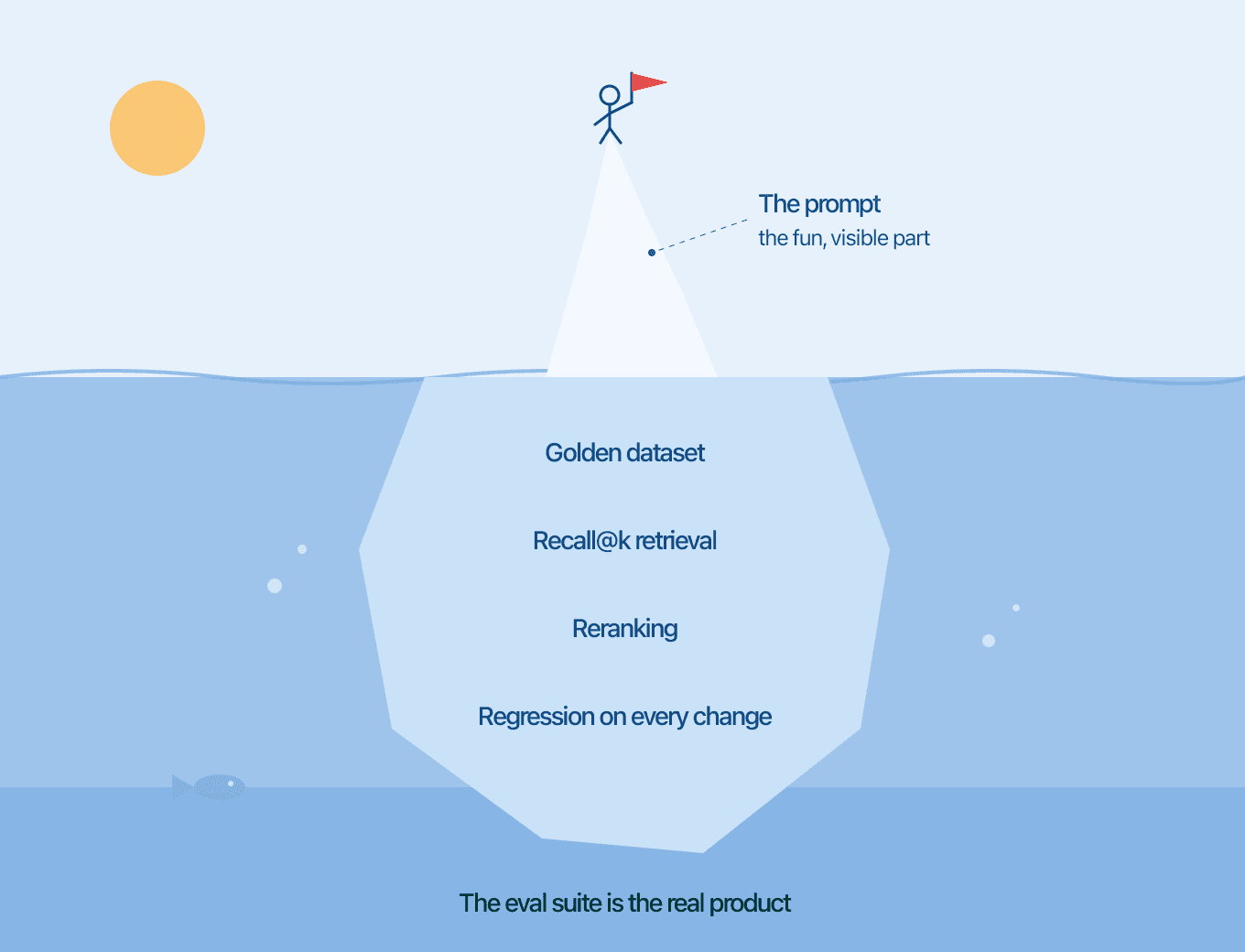
The shift that actually moved the needle was boring to say out loud: stop tuning the prompt by feel and start measuring it. The prompt is just a config value. Your evaluation suite is the thing you're really building.
The moment it clicked
We had a RAG pipeline answering questions over a client's internal docs. One week we "improved" the system prompt and three reviewers agreed it read better. We pushed it. Support tickets went up. The new wording had quietly broken a whole class of answers that the old phrasing handled fine. We had no way to know, because we had nothing to compare against.
So we built a golden dataset — real questions pulled from actual logs, paired with what a good answer should contain. Maybe 80 cases to start. The first time we ran our "better" prompt against it, it scored worse than the version from two weeks earlier. That was the whole lesson in one number.
What we learned tuning RAG specifically
The biggest surprise was where the errors actually came from. We assumed the model was the weak link. It wasn't — retrieval was. Most of our wrong answers traced back to the model never seeing the right chunk in the first place. No prompt on earth fixes that.
A few things that genuinely helped, in rough order of impact:
- Measure retrieval separately from generation. We track recall@k (did the right chunk make it into context?) before we ever judge the final answer. If recall is bad, the answer quality conversation is pointless.
- Chunking mattered more than the embedding model. Splitting on semantic boundaries instead of fixed token counts cut a surprising number of failures.
- Reranking earned its keep. A cheap reranker over the top 20 candidates beat pulling top 5 directly almost every time.
- LLM-as-judge works, but pin it down. We give the judge a rubric and few-shot examples, and we spot-check it against human ratings. An unconstrained judge drifts and flatters.
How we work now
Every change — prompt, chunk size, model version, retrieval parameter — runs against the eval suite before it merges. The suite is versioned in the repo like any other code. When a client reports a bad answer, that answer becomes a new test case, so the same failure can never silently come back. The eval set only grows, and it slowly becomes the most valuable artifact we own.
The uncomfortable truth is that the prompt is the easy, fun, visible part, so that's where everyone spends their time. But you can't improve what you can't measure, and a good eval harness is what turns "it feels better" into "it is better." Build that first. The prompt will follow.
Building something you need to trust in production?
This is exactly the kind of discipline we bring to client engagements — eval harnesses, retrieval tuning, and measurable AI systems that hold up after the demo. Get in touch and let's scope it.